 科技微讯
科技微讯Unicode 编码学习笔记
Unicode 11.0 有 137,374 characters,有 1,114,112 个 code points,最常用的 BMP 有 65,536 个 code points。
一些概念:
- codespace:1,114,112(0 ~ 10FFFF)
- codepoint:通常用一个 16 进制数字表示,为了表明这个数字是 unicode 的 code point,通常还会在前面加 U+。character 通过 code point 指代,所以 character 也可以用
U+数字表示,例如字母 A 是U+0041。 - encoded character
- encoding form:UTF-8、UTF-16 等,character encoding forms refer to integral data units in memory or in APIs, and byte order is irrele- vant; character encoding schemes refer to byte-serialized data, as for streaming I/O or in file storage, and byte order must be specified or determinable.
- encoding schemes:In the Unicode Standard, the specifications of the distinct types of byte serializations to be used with Unicode data are known as Unicode encoding schemes.
- unicode string:A Unicode string data type is simply an ordered sequence of code units.
- planes: 把 code space 划分成十多个 planes,每个 plane 包括 64k 个 code point,有趣的是,把每个 code point 编码都写成 5 个 16 位数字的话 ( 不足 5 位前面用 0 补充 ),那开头的那个非 0 数字就表示第几 plane,最后的 4 个数字表示这个 code point 位于这个 plane 的什么位置。第 0 plane 也叫 BMP,第 1 plane 也叫 SMP,第 2 个 plane 也叫 SIP,包含那些很少用的没有放在 BMP 的 CJK 文字,也包括一些常用的广东话文字。
- blocks: BMP 有大概 6.5 万个 character,这些都是最常用的 character,这些 character 又可以划分为大概 290 个类别,这些类别叫 block,这只是粗略的划分。
- combining character: In Unicode, combining characters are divided into two categories: spacing and non-spacing. Spacing combining characters are characters that have a visible width and are used to create ligatures and other complex characters. Non-spacing combining characters are characters that have no visible width and are used to modify the appearance of other characters.
UTF-8、UTF-16,这里的 8 和 16 不是 8 进制、16 进制的意思,意思 8 比特、16 比特的意思。UTF-8 的 code unit 是 8 比特,UTF-16 的 code unit 是 16 比特。因为 1 byte = 8 bits,所以 UTF-8 一个 code unit 就是 1 byte,UTF-16 的 1 个 code unit 就是 2 个 bytes。
计算机处理数据的方式,是处理那些固定长度的数字单元,这个长度通常是 8、16、32 等,又因为计算机只能识别 0、1 这种 binary digit,所以处理数据的方式就是 8 个或 16 个 binary digit,即 8bit 或 16bit 等。
code point 是一个 16 进制数字,为了让计算机处理这些 code point,需要把这些 16 进制数字转换成计算机可以识别的固定长度的 binary digit。
例如 004E 这个 code point,如何让计算机识别处理呢?分为两个步骤,首先转换成 binary digit,也就是 2 进制数字,结果是 1001110,接着思考把 1001110 转换成计算机习惯处理的固定宽度数字,如果转换成 8 个宽度的 binary digit,只需在前面加 0 凑够 8 位宽度只可,即写成 01001110。如果转换成计算机习惯处理的另一种固定宽度数字,比如 16 位,那就要在前面补充更多的 0,最后写成:0000000001001110。
当然不是所有 code point 都要补充这么多零,code point 的范围是从 0 到 10FFFF,对于最大的 code point 10FFFF,先转换成 2 进制的 binary digit,也就是 bit 数字,为:000100001111111111111111。再把它转换成 8 进制的固定宽度 binary digit,就变成:00010000 11111111 11111111。
需要注意的是,转换之后的数字,还不能被称为 UTF-8 编码,因为一些关键原因,UTF-8 需要在这些 code point 的 2 进制数字前面加一些前缀。 下图 xxxx 这些就是 code point 的 2 进制版本,对于前面提到的 004E,它的 2 进制数字就是 UTF-8 编码数字。而对于那些超过 1 个 code unit 的 code point,其 UTF-8 编码要加前缀。例如 10FFFF,它的 2 进制数字要填进 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 这里。
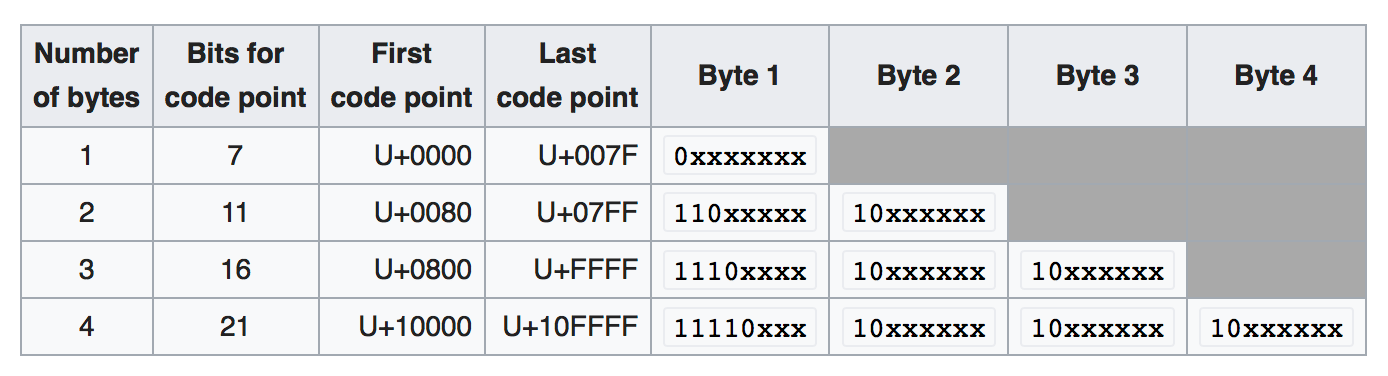
如果是 UTF-16,超过 1 个 code unit 的 UTF-16 编码这样写: 110110xxxxxxxxxx 110111xxxxxxxxxx。
不直接把 code point 的 2 进制数字当作 UTF-8 或 UTF-16,是为了避免所谓的 self-synchronization。看这个问题:为什么 UTF 要浪费几个 bit 的空间用于编码。
从 UTF-8 第一个字节的前面几个 bit,就可以马上判断这个 UTF-8 编码一共由多少个字节构成。
相关文章: